SEPIA
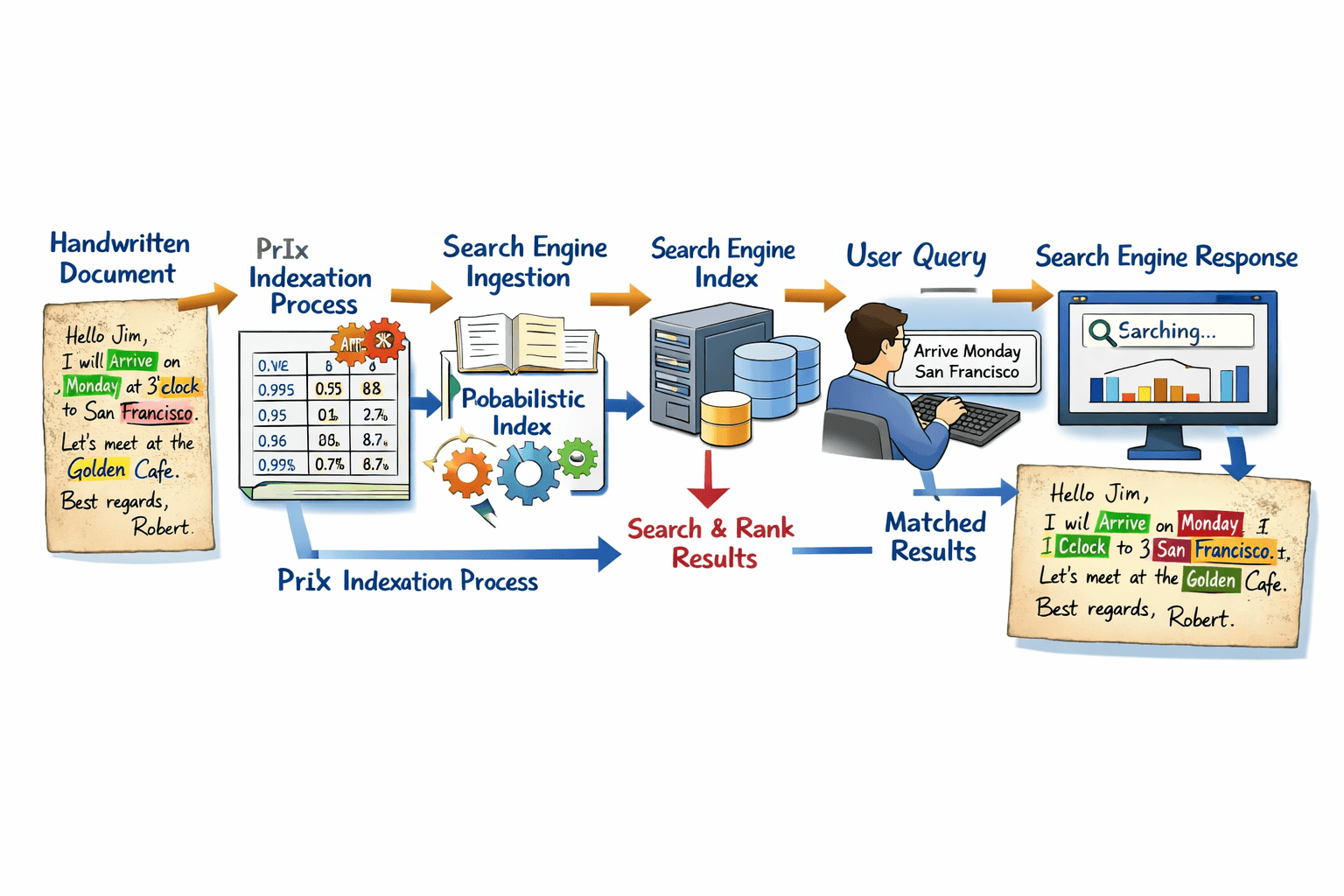
Motor de Búsqueda para Archivos Indexados Probabilísticamente (SEPIA, por sus siglas en ingés) es un proyecto de I+D centrado en mejorar significativamente la recuperación de información en documentos textuales, como manuscritos antiguos, mediante la investigación y el desarrollo de un motor de búsqueda eficiente y escalable. Este motor de búsqueda admite búsquedas simples y avanzadas en datos derivados de la indexación probabilística (PrIx) en conjuntos de cientos de miles a millones de imágenes.
El proyecto SEPIA representa un avance significativo en el archivado digital, al ofrecer un potente motor de búsqueda basado en la tecnología de indexación probabilística (PrIx). Diseñado para una integración fluida con los sistemas informáticos de los archivos existentes, SEPIA permite una transición fluida y maximiza el valor de las inversiones realizadas. Fundamentalmente, el proyecto mantiene las capacidades de PrIx a escala, lo que garantiza resultados de búsqueda robustos y precisos incluso con conjuntos de datos masivos. Además, SEPIA está diseñado para la eficiencia, ofreciendo un rendimiento rápido de indexación y recuperación, a la vez que optimiza el uso de recursos, lo que lo convierte en una solución altamente escalable para los archivos modernos.
Este proyecto ha sido apoyado con un 45% de financiación de la Unión Europea y del Instituto Valenciano de Competitividad e Innovación (IVACE), a través del PIDI-CV de la Comunitat Valenciana 2024, poniendo de manifiesto nuestro compromiso conjunto con la innovación tecnológica y el desarrollo sostenible de la región.
Páginas de muestra



Retos
PrIx es una tecnología altamente innovadora que permite indexar las imágenes a nivel de pixel en base a sus contenidos textuales inciertos. PrIx es una tecnología que suele considerarse disruptiva, ya que hace posible la búsqueda de información textual en colecciones de imágenes no transcriptas.
Para cada imágen de texto, se crea una especie de mapa de calor de palabras. Cada píxel de este mapa indica la mayor o menor probabilidad de que ese píxel forme parte de una o, generalmente, de muchas posibles palabras o secuencias de caracteres plausibles. Para una imágen típica, el índice probabilístico que representa este mapa contiene alrededor de 4000 hipótesis de palabras o secuencias de caracteres posiblemente escritas en la imagen, con sus correspondientes probabilidades y posiciones en la imágen. Como en una imágen suele haber alrededor de 200 palabras realmente escritas, esto corresponde a una densidad media de indexación de unas 20 hipótesis de palabra por cada palabra real. Esto constituye una enorme diferencia con respecto a una transcripción automática convencional que se obtiene mediante HTR, la cual solo proporciona una única hipótesis, la cual en muchos casos (especialmente en texto manuscrito) contiene errores significativos.
En la mayoría de colecciones de manuscritos históricos, alrededor del 30% de las palabras que se obtienen por medio de HTR suelen ser erróneas. Si se usaran solo esas palabras para indexar la colección, los resultados de la mayoría de búsquedas de información serían decepcionantes. Por el contrario, en un PrIx, si una palabra está claramente escrita, sin ambigüedades lingüísticas, y la imagen es de buena calidad, el número de hipótesis que se indexan es muy bajo; quizás una solo hipótesis en muchos casos. Pero en partes deterioradas de documentos, con tipos de escritura complejos y/o ambigüedades lingüísticas, se pueden llegar a indexar hasta varios
centenares de hipótesis por cada palabra real. Gracias a está densidad adaptativa de indexación, es posible finalmente detectar información textual precisa, incluso en las peores condiciones de la documentación analizada.
En resumen, los PrIx tratan de preservar la incertidumbre inherente a la interpretación como texto de los trazos que se observan en las imágenes; de esta forma se evita perder posibles interpretaciones que otros sistemas son incapaces de obtener.
Una vez se dispone de los PrIx’s de una colección de imágenes de texto, es relativamente fácil realizar búsquedas simples de texto en dichas imágenes. Los PrIx pueden estructurarse como una Base de Datos (BD) de contenidos textuales de las imágenes, en donde se guarda, para cada hipótesis de palabra, la secuencia de caracteres que la conforman, su verosimilitud o probabilidad de relevancia (PR) y la información geométrica correspondiente a su posición en la imágen.
Toda esa información se puede almacenar en una base de datos comercial (p.e.j SQL) y utilizar el motor de búsqueda de dicha BD para realizar búsquedas simples de texto libre, en el cual una palabra es relevante para una búsqueda dada si la secuencia de caracteres que la conforman es igual a la búsqueda realizada y la PR de la misma es superior a un umbral definido por el usuario.
No obstante, esta aproximación tiene limitaciones importantes debido a la enorme cantidad de información probabilística y geométrica proporcionada por los PrIx y al post-proceso de filtración que se debe realizar para las hipótesis que no superen el umbral de PR. Dichas limitaciones se ven multiplicadas cuando la intención es realizar búsquedas avanzadas, en las cuales la relevancia de un documento depende de dos o más hipótesis. Por ejemplo, búsquedas del tipo «x AND y» en las cuales las hipótesis de un documento son relevantes únicamente si la PR conjunta de barbas palabras «x» y «y» es superior al umbral definido por el usuario. O, en el caso de búsqueda difusa, donde el sistema debe ser capaz de obtener todas las hipótesis que sean “similares” a la palabra de búsqueda y que a la vez su PR sea superior al umbral.