SEPIA
Search Engine for Probabilistically Indexed Archives (SEPIA) is an R&D project focused on significantly enhance information retrieval within textual documents, such as ancient manuscripts, through the research and development of an efficient and scalable search engine. This search engine supports both simple and advanced searches on data derived from probabilistic indexing (PrIx) across sets of hundreds of thousands to millions of images.
The SEPIA project represents a significant advancement in digital archiving, delivering a powerful search engine built around Probabilistic Indexing (PrIx) technology. Designed for seamless integration with existing archives IT systems, SEPIA allows for a smooth transition and maximizes the value of existing investments. Crucially, the project maintains PrIx capabilities at scale,ensuring robust and nuanced search results even with massive datasets. Furthermore, SEPIA is engineered for efficiency, delivering rapid indexing and retrieval performance while optimizing resource utilization, making it a highly scalable solution for modern archives.
This project has been supported with 45% funding from the European Union and the Valencian Institute of Competitiveness and Innovation (IVACE), through the PIDI-CV of the Valencian Community 2024, highlighting our joint commitment to technological innovation and sustainable development in the region.
Sample Pages



Challenges
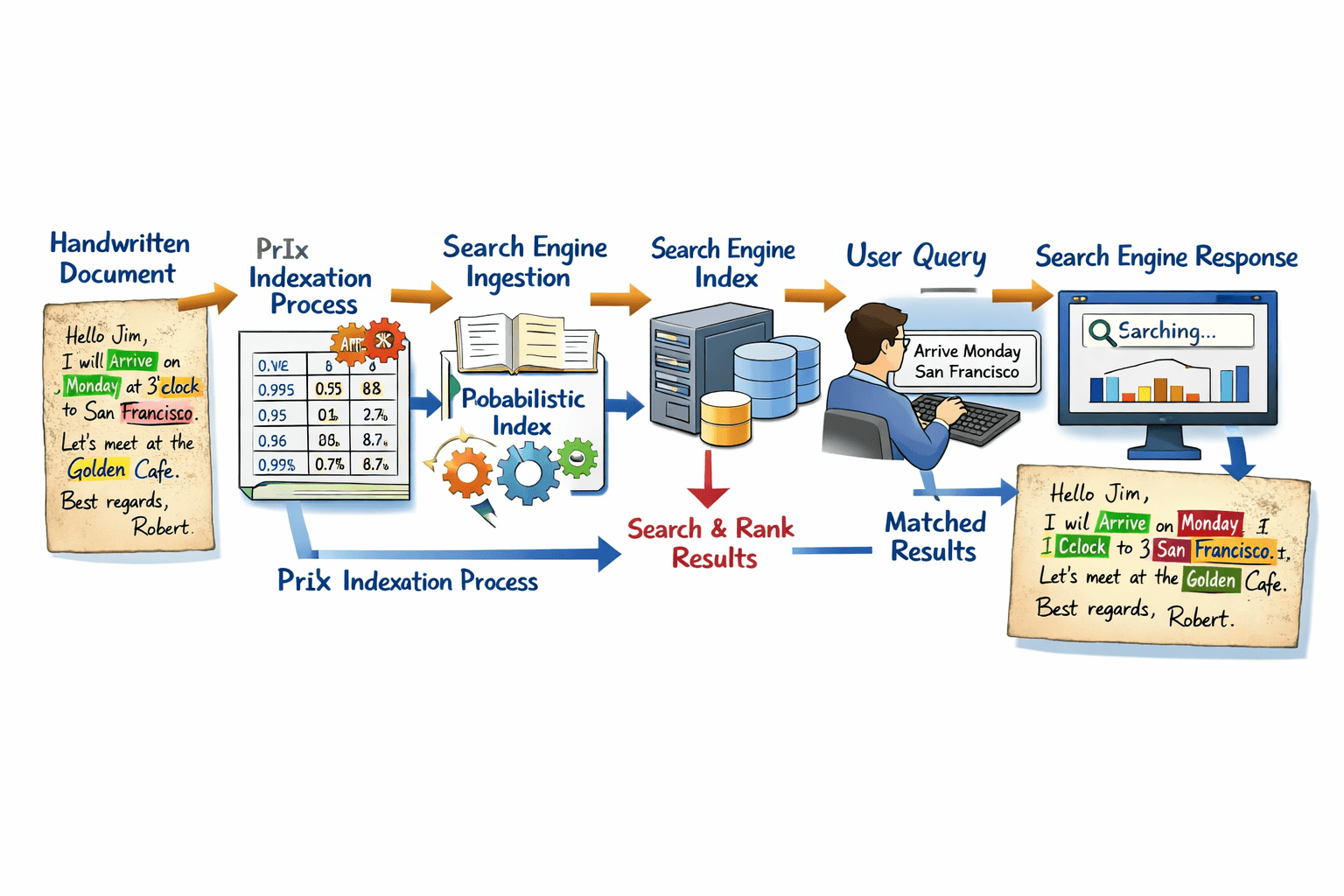
PrIx is a highly innovative technology that allows images to be indexed at the pixel level based on their uncertain textual content. PrIx is often considered a disruptive technology because it makes it possible to search for textual information in collections of untranscribed images.
For each image of text, a kind of word heat map is created. Each pixel in this map indicates the greater or lesser probability that that pixel is part of one, or generally, many possible words or plausible character sequences. For a typical image, the probabilistic index represented by this map contains around 4,000 hypotheses of words or character sequences possibly written in the image, with their corresponding probabilities and positions within the image. Since there are usually around 200 words actually written in an image, this corresponds to an average indexing density of about 20 word hypotheses for each actual word. This represents a significant difference compared to conventional automatic transcription using HTR, which only provides a single hypothesis that, in many cases (especially with handwritten text), contains significant errors.
In most collections of historical manuscripts, around 30% of the words obtained through HTR are typically erroneous. If only these words were used to index the collection, the results of most information searches would be disappointing. In contrast, with PrIx, if a word is clearly written, without linguistic ambiguities, and the image is of good quality, the number of hypotheses indexed is very low; perhaps only one hypothesis in many cases. But in deteriorated sections of documents, with complex handwriting styles and/or linguistic ambiguities, up to several hundred hypotheses can be indexed for each actual word. Thanks to this adaptive indexing density, it is finally possible to detect accurate textual information, even in the worst conditions of the analyzed documents.
In summary, the Prix systems try to preserve the uncertainty inherent in interpreting the strokes observed in the images as text; in this way, possible interpretations that other systems are unable to obtain are avoided.
Once the Prix values (PrIx) of a collection of text images are available, it is relatively easy to perform simple text searches within those images. The Prix values can be structured as a database (DB) of the images’ textual content, where, for each word hypothesis, the character sequence that makes it up, its likelihood or probability of relevance (PR), and the geometric information corresponding to its position in the image are stored.
All this information can be stored in a commercial database (e.g. SQL) and the database’s search engine can be used to perform simple free-text searches. In these searches, a word is relevant if its character sequence matches the search term and its PR exceeds a user-defined threshold.
However, this approach has significant limitations due to the enormous amount of probabilistic and geometric information provided by the Prix values and the post-processing of filtering that must be performed for hypotheses that do not meet the PR threshold. These limitations are compounded when the intention is to perform advanced searches, in which the relevance of a document depends on two or more hypotheses. For example, searches of the type “x AND y” where the hypotheses of a document are relevant only if the combined PR of the words “x” and “y” is greater than the threshold defined by the user. Or, in the case of fuzzy search, where the system must be able to obtain all hypotheses that are “similar” to the search term and whose PR is also greater than the threshold.