Automatic Segmentation and Classification
Segmentation and Classification
At tranSkriptorium, apart from being specialists in automatic handwritten text recognition, we offer document segmentation and classification services to transform large volumes of archival material into structured, understandable, and manageable collections.
Segmentation is the process of identifying segments that make up a text and organizing them into coherent blocks of information, which may span from a few paragraphs to on or several pages. Once segmented, if was necessary, each block can be classified into predefined categories based on its content, enabling the automation of organization and search.
Advantages
Among others, segmentation and classification offer highly demanded advantages:
- Optimized search: enhances navigation, searches and sorting, ideal for archivists, researchers, and the general public.
- Automated organization: simplifies administration, access control, and reduces the workload of manual tasks.
- Prepared for future analysis: this process, whether applied in full or partially, could facilitate a future analysis of the collection.
Sample Pages

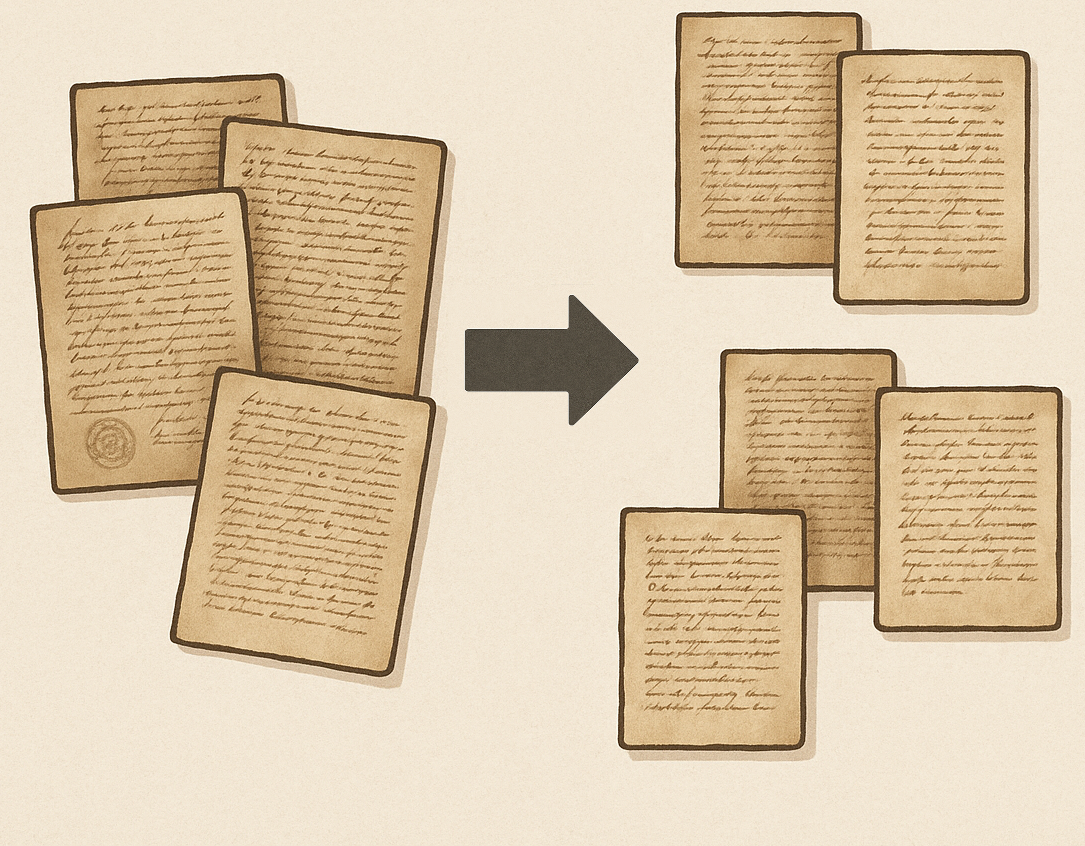
Challenges
The greatest challenges in segmentation and classification lies in the accurate annotation of the training samples, as well as the quality and balance of those samples. To ensure precise results, each segment must be carefully annotated by transcribers with the correct information and its predefined class. A carefully selected, highly representative subset of the collection to be segmented and classified (Ground Truth) is essential. The most common and critical issues include:
- Class ambiguity: sometimes, even for experienced transcribers, manually dividing an existing text into coherent segments or identifying the type of document it represents is a complex task. In some cases, a document may not fit clearly into a predefined class. These types of errors are critical.
- Class imbalance: it is common to find many documents of one class and only a few of another within a collection. This imbalance requires specific compensation techniques during training.
- Text quality: classification and segmentation rely heavily on the quality of the textual content. Poorly preserved text or inaccurate transcription, manual or automatic, leads to poor segmentation and classification. In the case of handwritten text (our speciality), high quality text recognition is essential.
Results
pages
Segmentation
To evaluate the quality of segmentation, we use the Content Alignment Error Rate (CAER), which measures how much information from one segment has been incorrectly assigned to another segment it does not belong to. Therefore, the lower the CAER, the better the segmentation performance.
The segmentation process covers two general cases:
- Cases where an entire page belongs to a single segment.
- Cases where different pages may contain distinct segments.
For the first case, the segmentation achieved a CAER below 5%. And for the second case, some collections achieved a CAER below 3%.
Classification
For classification, since the output is binary, we use the Error Rate (ER) as a standard metric. This indicates the percentage of documents incorrectly classified out of the total. As with segmentation, a lower ER means better classification.
In the case of archival documents, which included classifications such as powers of attorney, wills, sales, transfers, etc; we achieved an ER of less than 6%.