ExtraDoc
ExtraDOC (from Spanish Extracción de Información de Imágenes de Documentos de Texto) is an R&D project focused on advancing the capabilities of the PrIx suite of tools. The project aims to develop specialized Machine Learning techniques for extracting and analyzing information directly from images of text documents. Particualrly complex handwritten documents.
Objectives:
The core goal of ExtraDOC is to enable comprehensive document analysis and cataloging procedures without the need for full text transcription. To achieve this, the project integrates and enhances sever key capabilities into the PrIx ecosystem:
- Document Classification: PrIx enables automatic classification of documents into predefined categories using it’s custom representation of the textual content of the document.
- Document Segmentation: ExtraDOC supports segmentation of documents into meaningful sections. Simple documents can be segmented using image analysis alone, while complex documents benefit from combining image features with textual understanding derived from PrIx outputs.
- Text Analytics: The project introduces methods to extract and analyze textual information (e.g. names, places, dates, quantities) and statistics from handwritten documents.
- Searching and extracting semantic information: ExtraDOC goes beyond surface-level content to extract semantic relationships within documents. This includes identifying structural relationships in tables or forms (key-value), enabling mode advanced sear and retrieval capabilities.
ExtraDOC has demonstrated the power and flexibility of the PrIx suite in handling complex handwritten documents, making significant progress in the field of document image analysis. Its ability to perform robust information extraction without transcription opens up new possibilities for processing historical archives, administrative records, and other document sources at scale.
This project has been subsidized the “Centro para el Desarrollo Tecnológico e Industrial (CDTI)” under the Neotec2022 program (EXP00152032/SNEO20222386).
Sample Pages
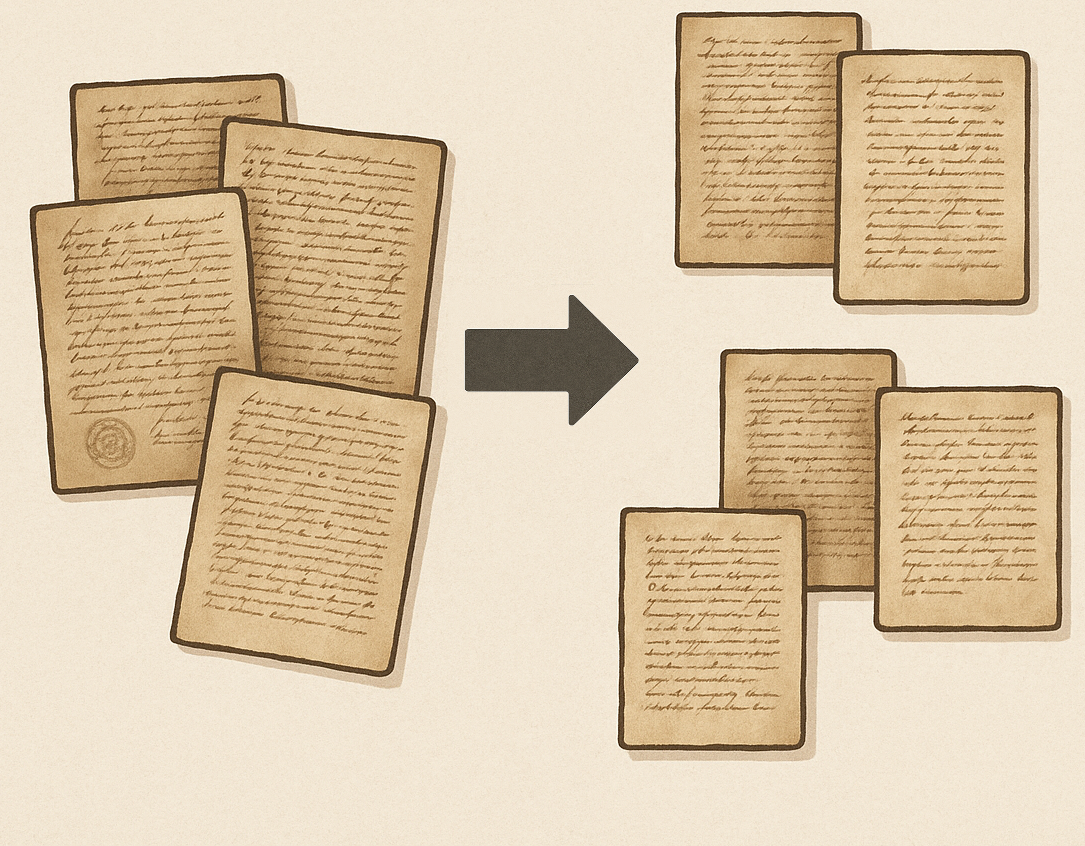



Challenges
One of the main challenges faced in the ExtraDOC project was the inherent complexity and variability of handwritten documents.
These documents often feature diverse layout and degradations, including physical deterioration, stains, and overlapping ink, which severely limit the reliability of standard image processing and recognition techniques.
In addition, the documents frequently include multiple languages and a wide range of handwriting styles —many of which are highly irregular or difficult to read. Writers also rarely adhered strictly to structured formats such as tables or forms, often placing information freely across the page, which complicates the extraction of structured data.
For tasks like classification and segmentation, another significant difficulty was that document categories are often implicit and not directly stated in the text. Instead, the system has to learn to infer the class or structure of a document based on contextual clues, layout patterns, or visual and semantic elements, requiring robust machine learning models capable of handling noisy, ambiguous, and weakly-labeled data.