News

Providing True Open Access to Digitalized Content
At tranSkriptorium we are offering disruptive technology that we believe will change how humanity accesses and consumes digitalized content.
To make a simile access and consumption of digitalized content is currently in the state the internet was around the early 90's. Although the internet could be said to have been invented in the 70's a lot had to happen on how content was served and made searchable in order to reach its current user friendly status.
Initially one had to know the actual address that would serve the content they wanted to read. They passed through an era of having directory listings in public FTP servers. Later those listings were indexed and made searchable by title in 1990. During 1991 to 1993 a lot of innovation on how to search the contents of the internet was performed: searches by keywords defined by the admins, updated listings by manual alerts, manually generated index files for each web, ...

It was not until late 1993 that the first search engines that depended on web crawlers and automatically generated indexes appeared. This is the base technology that fuels how we consume information from the internet nowadays and that made it viable for mass consumption. This technology made possible searching by content.
But, What is the current status of access to digitalized content? Digitalization is an important step that preserves the information of the physical document and makes it accessible through a computer and thus a network. But this is akin to the beginnings of the internet where one had to go page by page in order to find the content it was searching for. At best, experts have added meta-information with titles, dates and maybe some keywords or a summary but searching by actual content is not possible. Furthermore, this is a manual endeavor and is not something that can scale.
Current solutions
One could naively think to use a standard OCR motor and search on the transcribed text, but this could only yield adequate results in modern printed text scanned perfectly. Additionally, the transcription will still contain errors (yes, even in these easy texts) and if we are searching for content by words we are going to be missing out on results. Even modern HTR engines based on machine learning have issues, specially with documents from other areas (trust us, we have our own world class HTR engine).
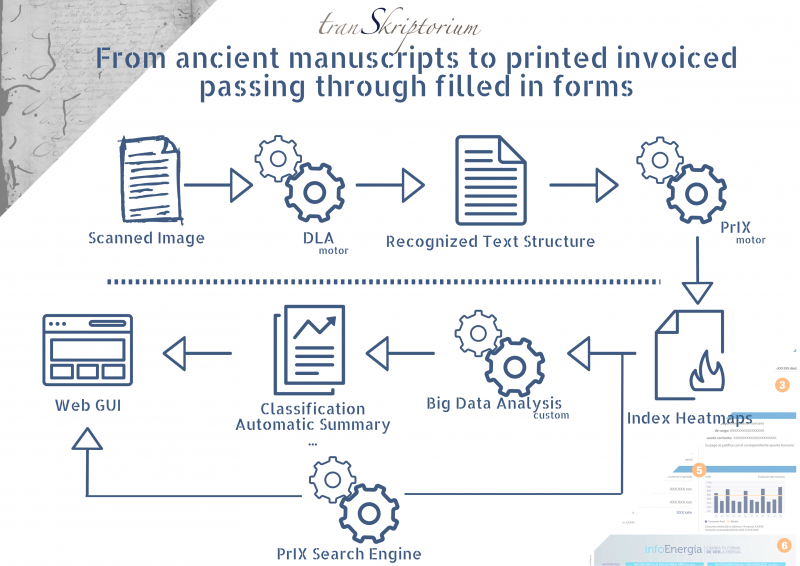
To by-pass all these issues we have developed (20 years in the making and validated through national and EU projects) PrIX, an indexing technology that provides a kind of heat-map for each image with the probability of each possible word in each pixel. We don't search on one transcription and hope for the best, we search on all <
With these automatically generated indexes are able to perform content based searches on the contents of the digitalized pages. These indexes can be consumed via Elastic Search, SOLR,... or queried via our very own search engine that provides searching capabilities that exceeds what can be done in most commercial packages. Over and above this, as we will know have true open access to the contents of digitalized documents launching Big Data Analysis on them in no longer a dream Classification, Automatic summary generation, information retrieval, ... on documents of all types are a reality.
We are entering an era where the frontier between digital and digitalized documents will be blurred, and maybe, even rendered non-existent. Do you want to enter it with us?
For more information visit us at tranSkriptorium.com or directly contact our CEO Luis Antonio Morró González.